Site Reliability Engineering Audiobook
3 Oct 2025 #pythonRecently I wanted to revisit some chapters from the great SRE Book while on the go. Unfortunately, I was not able to find an audio version of it. Below is the description how one could make it oneself.
Read Aloud
Easiest solution to listen to this book on a mobile phone would be to open it in Chrome and then click Listen to this article. That works, but has some drawbacks:
- Book is published as multiple separate pages, need to switch them manually
- No bookmarks, listening position gets reset when you have interruption for a couple of days
- Audio stops after some time when you turn off the screen. Need to keep screen on
- Need internet connection
That could be fixed by @Voice Aloud Reader. Unfortunately its actual voice quality is worse than in Chrome.
Another options would be Elevenreader and Speechify:
- Quality is much better than in Chrome
- Limits to 2h/week, and internet connection is required
Ok, let’s see how hard it is to get a “good old” mp3 files for an audiobook player.
Model
At the time of this writing, top TTS model at huggingface is Kokoro-82M
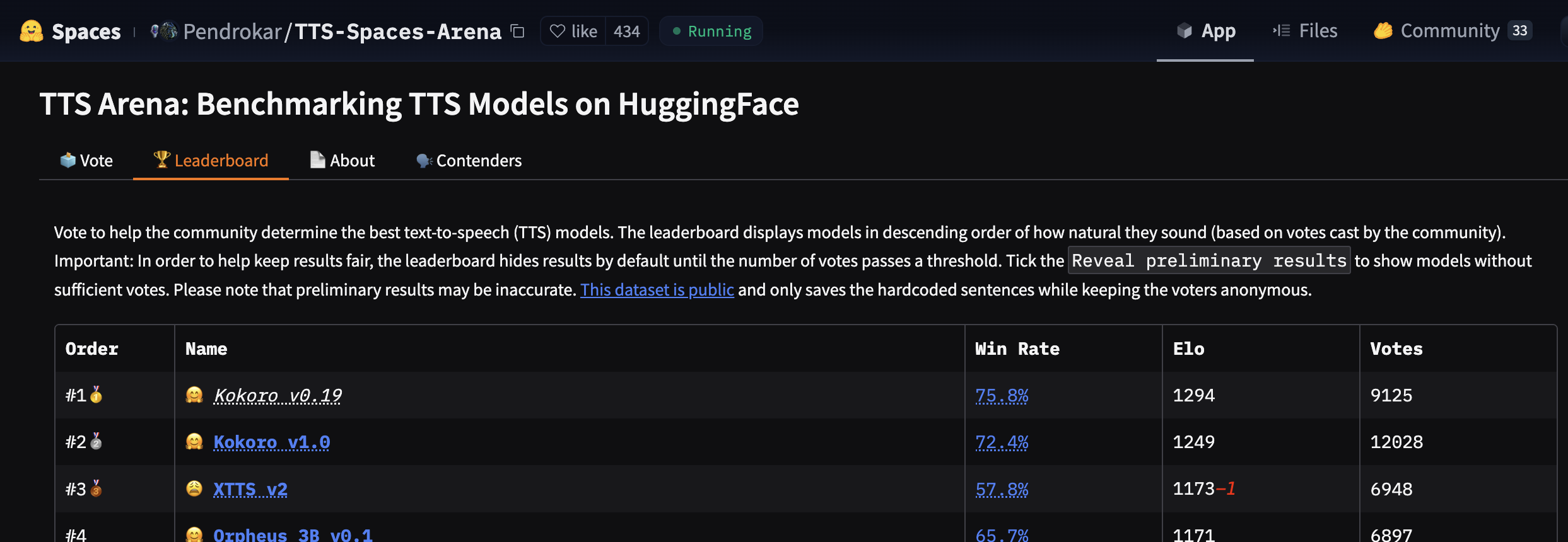
It does not have “voice cloning” as in XTTS2. But it is still fully self-hosted and of a better audio quality, as shown by TTS-Spaces-Arena:
Also, it has a docker distribution via remsky/Kokoro-FastAPI, so could be started as simple as:
docker run -p 8880:8880 ghcr.io/remsky/kokoro-fastapi-cpu
Then you can open web UI at http://localhost:8880/web/ and check the output quality on some text examples. Which sounds pretty great!
But how to get the input, i.e text from a bunch of html pages?
HTML to Text
Let’s start with Table of Contents:
https://sre.google/workbook/table-of-contents/
Need to parse this page, and get title and url for each chapter. For example, with something like this:
def getLinks(url: str) -> List[tuple]:
res = []
base = '/'.join(url.split('/')[0:3])
page = requests.get(url).content
content = BeautifulSoup(page, 'html.parser').find(id="content")
for link in content.find_all('a'):
ref = link.get('href', '')
if ref.startswith('/'):
ref = base + ref # make absolute link
if ref == url:
continue # link to TOC itself
res.append((link.text.strip(), ref))
return res
Now for each url, we need to get page content as a text. Let’s also drop first <h1> tag with name of the chapter. Because we already know it from the Table of Contents. (And I prefer announcement like “Chapter 6 - Eliminating Toil”, instead of just “Eliminating Toil” from the page itself)
def getText(url: str) -> str:
page = requests.get(url).content
content = BeautifulSoup(page, 'html.parser').find(id="content")
content.find('h1').extract() # remove first H1, as it is the same as link title
return content.text
And that’s it!
Now let’s stitch that together, and save each chapter as a separate file named {num}-{title}.mp3.
Another thing which I want to add, is a chapter title announcement in the beginning with a short pause afterwards. Unfortunately, there is no tags support in Kokoro. Quick solution would be to use ;-, chars, while proper solution is to actually generate silence.
So, here is the full version of a quick scraper:
import requests
from typing import List
from bs4 import BeautifulSoup
def getLinks(url: str) -> List[tuple]:
res = []
base = '/'.join(url.split('/')[0:3])
page = requests.get(url).content
content = BeautifulSoup(page, 'html.parser').find(id="content")
for link in content.find_all('a'):
if (ref := link.get('href', '')) == '':
continue
if ref.startswith('/'):
ref = base + ref
if ref == url:
continue
res.append((link.text.strip(), ref))
return res
def getText(url: str) -> str:
page = requests.get(url).content
soup = BeautifulSoup(page, 'html.parser').find(id="content")
soup.find('h1').extract() # remove first H1, as it the same as link title
return soup.text
def generate(input, filename: str):
response = requests.post(
"http://localhost:8880/v1/audio/speech",
json={
"model": "kokoro",
"input": input,
"voice": "am_michael(2)+am_santa(1)",
"response_format": "mp3", # Supported: mp3, wav, opus, flac
"speed": 1.0,
"normalization_options": {
"normalize": False
}
}
)
with open(filename, "wb") as f:
f.write(response.content)
if __name__ == "__main__":
i = 0
for link in getLinks("https://sre.google/workbook/table-of-contents/"):
print(link[0])
text = f"{link[0]}.\n;-,;-,;-,;-,;-,;-\n\n" # chapter announcement
text += getText(link[1])
generate(text, f'{i:03}-{link[0]}.mp3')
i += 1
Performance
Let’s take for example this page: https://sre.google/workbook/foreword-II/
Audio version of it has duration of 12m18s
2m42sis the audio generation time on Apple M3 CPU, so generation speed is ~5x of a playback speed.4m43s(~2.6x) on AMD Ryzen 5500, just for comparison.1m15s(~10x) on Apple M3, by moving from FastAPI to locally running kokoro on CPU.
There is even an option to enable GPU acceleration for Mac viaPYTORCH_ENABLE_MPS_FALLBACK=1but it does not work, needs mlx.27s(~27x) on Apple M3 GPU, by running FastAPI locally via./start-gpu_mac.sh15s(~50x) on RTX 5080, by running FastAPI GPU docker container in WSL2 (needs sm-120 workaround)11s(~67x) on RTX 5080, by running kokoro directly in WSL2
Using GPU, resulting times for the whole book:
- “SRE book” total duration is
22h02m, audio generation time is19m03s - “SRE workbook” total duration is
17h53m, audio generation time is16m30s
Alternatives
https://github.com/yl4579/StyleTTS2
https://github.com/matatonic/openedai-speech
https://github.com/p0n1/epub_to_audiobook
https://eamag.me/2025/Voice-Cloning
Even better solution would be to use html-to-markdown and then use some paid stuff like https://www.openai.fm, where you can fine tune tone and emotions. But let’s leave it for non-techical literature)